做SEO的人,每天跟搜索引擎打交道。但老铁SEO问你一个问题:搜索引擎到底是怎么把一个网页从互联网的某个角落里捞出来,然后排到搜索结果第一页的?
大部分人能说出“爬虫抓取、建立索引、算法排序”这三步。但这就像问汽车怎么跑的,你说“踩油门车就动了”——没错,但不知道发动机怎么点火、变速箱怎么换挡、刹车怎么介入,车半路熄火了你就只能蹲在路边抽烟。
老铁SEO今天把搜索引擎从发现你的页面到把它排到搜索结果里的全流程,拆成七个环节,一个环节一个环节讲清楚。不讲大学教材里的理论,只讲跟SEO实战有关的那部分。
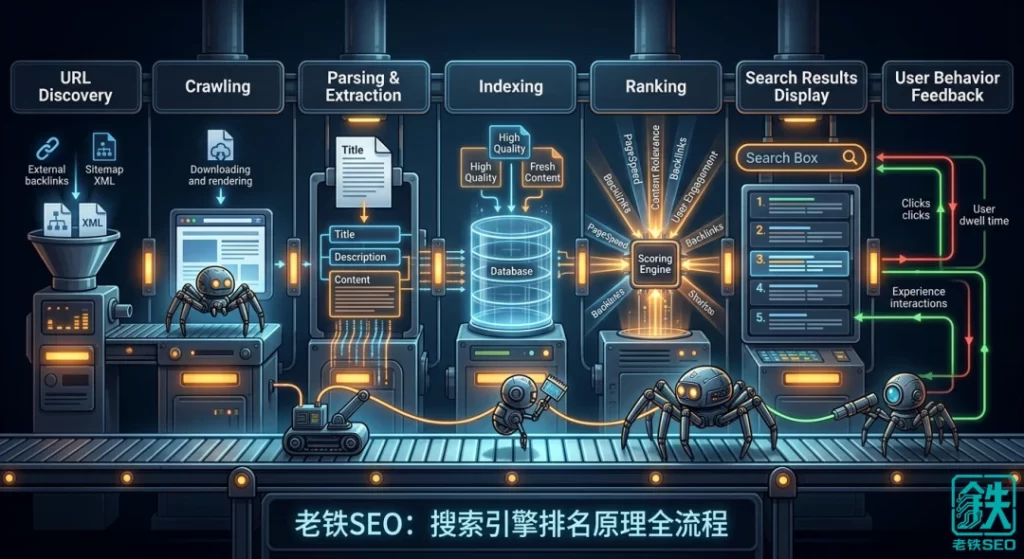
一、发现URL:你的页面得先被搜索引擎知道
搜索引擎不是全知全能的。它不会凭空知道你在某个服务器上新建了一个页面。你必须通过某种方式让它的爬虫发现这个URL。
怎么被发现?第一条路是外链。搜索引擎的爬虫在抓取一个已经被它收录的页面时,会提取这个页面上所有的外链,把还没见过的URL加入待抓取队列。这就是为什么外链能加速收录——不是你买了条外链搜索引擎就给你加分,而是那条外链所在的页面把搜索引擎的爬虫带到了你家门口。
第二条路是站长平台的URL提交。百度有链接提交接口,谷歌有Search Console的URL检查工具,手动提交或者通过API批量提交。这条路对新站最重要,因为新站没有外链,搜索引擎没有别的途径发现你的页面。
第三条路是XML站点地图。你在网站根目录放一个sitemap.xml,里面列出了你网站上所有想让搜索引擎抓取的URL。爬虫定期会来读这个文件,把里面新增的URL加入待抓取队列。
这三条路不是三选一,是三条都得走。外链给你广度,提交给你速度,站点地图给你完整性。只走一条路,你的页面被发现的效率会大打折扣。
二、抓取:爬虫来了,但它不是什么都抓
搜索引擎发现了你的URL,把它放进了待抓取队列。但队列里的URL可能有几百亿个,什么时候轮到你?这取决于你的抓取预算。
抓取预算是一个网站在搜索引擎那里被分配到的抓取资源额度。你的网站权重越高、内容更新越规律、服务器响应越快,搜索引擎给你的抓取预算就越多。谷歌的Gary Illyes原话是:“我们把抓取预算定义为搜索引擎在特定时间内愿意抓取一个网站的URL数量。”
这里有一个很多人不知道的细节:爬虫在抓取你的页面时,会先检查这个页面的robots.txt有没有禁止抓取、HTTP响应头有没有异常。如果一切正常,爬虫会下载这个页面的HTML源代码。但这只是第一步。
下载完HTML之后,搜索引擎会把页面放进一个渲染队列。因为现在的网页大量依赖JavaScript动态加载内容,爬虫拿到的HTML可能只是一堆JS代码和空的div标签。搜索引擎需要用无头浏览器把这个页面真正渲染出来,看到用户在浏览器里看到的样子。渲染这一步极其消耗计算资源,所以搜索引擎的渲染队列和处理能力是有限且被严格控制的。
如果你的页面关键内容全部依赖JS动态加载、服务器端没有做预渲染,搜索引擎的爬虫下载了你的HTML但渲染队列排不上或者渲染失败,你在搜索引擎眼里就是一个空白页面。SPA单页应用和大量依赖动态加载的网站很容易栽在这个坑上。
三、解析与提取:搜索引擎开始“读懂”你的页面
页面被抓取并渲染完成之后,搜索引擎的解析器开始工作了。它干这几件事:从HTML标签中提取页面的标题、描述、H标签、图片ALT属性、结构化数据标记等结构化信息。把页面的正文文本提取出来,去除HTML标签、去除导航栏和页脚的重复文本,得到纯净的正文内容。把正文内容进行分词——中文分词是一个巨大的技术挑战,搜索引擎需要把连续的汉字字符串切分成一个个有意义的词。提取页面上所有的链接,把它们分成内部链接和外部链接,放入不同处理流程。识别页面的规范URL——通过canonical标签、301重定向、或者内容相似度比对,确定这个页面的规范版本是什么。
这一步对SEO的启示非常直接:你的结构化数据标记越准确,搜索引擎对你的理解越到位。你的正文占比越高,搜索引擎的信号越集中。你的分词友好度越高,关键词匹配越精准。
四、索引:不是收录了就完事了
一个页面被解析完之后,搜索引擎会决定要不要把它加入索引库。索引库是搜索引擎存放所有“可被搜索到的页面”的超大数据库。
但很多人把“收录”和“被索引”混为一谈。你在百度site一下你的URL,发现有结果,说明这个页面被收录了。但这个页面在索引库里被分配到了什么位置、被调用的优先级高不高,这是索引质量的问题。
搜索引擎在索引阶段会对页面做一个初步的质量评估:这个页面是不是有实质内容的,还是低质壳页面;这个页面跟你的网站整体主题是否相关;这个页面有没有作弊嫌疑——关键词堆砌、隐藏文字、恶意跳转等。初步质量评估的结果,会直接影响这个页面在排序阶段的“起始分”。
还有一个容易被忽视的概念叫“索引清理”。搜索引擎会定期清理索引库里长期没有更新、长期没有用户点击、内容过时或已被删除的页面。这就是为什么有些老页面过段时间site就找不到了——不是被惩罚了,是被搜索引擎的自然清理机制移出了索引库。
五、排序:几百个因子一瞬间算出一个结果
当用户在搜索框里输入一个查询词,搜索引擎就会在索引库里检索跟这个词相关的页面,然后通过排序算法把这些页面从好到差排列呈现给用户。
排序阶段是搜索引擎花费最多工程精力的地方。现代搜索引擎的排序算法包含几百个甚至上千个因子,这些因子可以分成几大类:
相关性因子:页面跟用户查询词的相关程度。
关键词是否匹配,匹配位置在哪里——标题里出现权重比正文里出现高,正文前部出现权重比尾部出现高。页面是否覆盖了查询词背后的搜索意图——用户搜这个词是想买、想学、还是想找某个网站。
权威度因子:页面和页面所在网站的权威程度。
外链的数量、质量、多样性。域名的历史信任分。网站的行业权威性。
用户体验因子:页面的加载速度。
移动端适配程度。页面是否有侵入式广告影响阅读。用户行为信号——用户从搜索结果点进来之后有没有马上返回搜索结果页、在页面上的停留时间、浏览深度。
内容质量因子:内容的原创性、深度、全面性。
内容的时效性——跟用户查询的时间需求是否匹配。内容的E-E-A-T——经验、专业度、权威性、信任度。内容的可读性和结构清晰度。
上下文与个性化因子:用户的地理位置。
用户的搜索历史和偏好。用户当前使用的设备类型。
所有这些因子在被加权计算之后,搜索引擎得到一个综合得分,按分数从高到低排列搜索结果。
六、排序之后还有故事:搜索结果的持续调整
很多人以为排名是一次性算出来就固定了。不是。搜索结果展示给用户之后,用户的点击行为会反过来影响排名。用户点进了你的页面,在里面待了很长时间没有返回,说明你的页面满足了他的需求。用户点进你的页面几秒就关掉返回搜索结果,说明你的页面没能解决问题。
搜索引擎会把所有用户的这类行为数据收集起来,用来校准它的排序模型。这也是为什么同一个关键词在不同时间段、不同设备上、不同地域搜索会看到不同的结果。这也是为什么你的排名即使不做任何改动也会波动——不是你的页面变了,是整个排序生态中其他页面的表现和用户行为在持续变化。
谷歌的RankBrain和百度的用户行为模型现在都会对排名进行实时微调,这部分引擎的自我学习能力是SEO从业者无法直接干预但能间接影响的。
七、从全流程看SEO
把以上全流程串起来,你会得到一个看待SEO工作的全景视角。
- 技术SEO解决爬行和抓取阶段的问题——robots.txt配置、抓取预算利用效率、服务器性能、渲染质量、结构化数据标记。
- 内容SEO解决解析和索引阶段的问题——内容结构清晰、关键词覆盖合理、语义丰富度、满足搜索意图。
- 外链建设解决排序阶段权威度因子的问题——高质量外部推荐、相关行业认可。
- 页面体验优化解决用户体验因子的问题——加载速度、移动端适配、用户行为信号。
- 持续更新维护解决索引清理和排序持续调整阶段的问题——网站保持活跃、内容保持新鲜度。
任何一个环节出问题,都会卡住排名你上不去:
- 技术没问题、内容一般,排名能上但很快掉;
- 内容好技术差,爬虫根本看不到你的好内容;
- 内容好技术好外链差,基础排不进去;
- 所有都好但页面体验差,大量用户从搜索点进来后秒退,排名最终也会掉。
搜索引擎把你从一个没人发现的角落拉到搜索结果第一页,是对你所有环节综合得分的加权反馈。你的目标是让每个环节都不滑坡,而不是指望某一天在某一项上突然满分。
评论0